
ファイル + フォルダ 一覧取得 も可能!【 Python 】
k.w
SEへの道

Python + OpenCV で 一文字 画像 が自動的に出力出来る様になったら、一つの フォルダ に雑多に保存するのではなく、 OCR を使って、自動的に分別してくれたら、便利ですよね?なら、やってみましょう!OCRの精度もキーになりますが、まずは 振り分け することから。
ある単語のm時列を含む画像から、一文字ずつ分離しそれぞれをOCRすれば、出来そうな気がします。
ということで、まずは振り返りから。
(基本を確認したい場合も以下リンクから!)
[https://way2se.ringtrees.com/py_cv2-005/]
[https://way2se.ringtrees.com/py_ocr-001/]
後は、OCR結果から、フォルダに振り分けるところが出来れば、ばっちりですね。
では、結果イメージとサンプルコードを共有します!
まずは結果から。
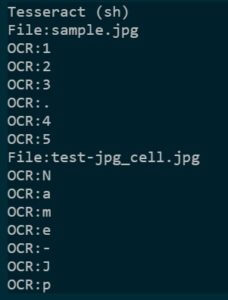
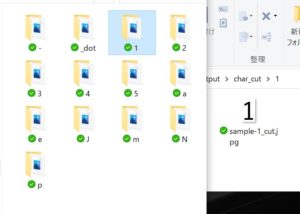
ちゃんと認識されてます!
余白も功を奏しているのかな?[https://way2se.ringtrees.com/py_ocr-002/]
続いてサンプルコードです。(長文ですがご容赦。)
/* import設定 */
import os
import glob
import cv2
import sys
import configparser as cfg
import numpy as np
import pandas as pd
from operator import itemgetter
import pyocr
import pytesseract
user = os.getlogin()
/* Config設定 */
cfg = cfg.ConfigParser()
cfg.read('config.ini', 'UTF-8')
/* OCR設定 */
tools = pyocr.get_available_tools()
if len(tools) == 0:
print("No OCR tool found")
sys.exit(1)
tool = tools[0]
lang = 'eng', 'jpn'
print(tool.get_name())
/* File読み込みフォルダ指定 */
files = glob.glob(cfg.get(user, 'img_folder') +
'/cell_cut/*.jpg', recursive=True)
/* File読み込み(複数可) */
for file in files:
filename = os.path.basename(file)
print('File:' + filename)
img = cv2.imread(file, cv2.IMREAD_GRAYSCALE)
kernel = np.ones((2, 2), np.uint8)
img = cv2.erode(img, kernel, iterations=1)
ret, img = cv2.threshold(img, 150, 255, cv2.THRESH_BINARY)
minlength = int(img.shape[0] * 0.1)
gap = 0
lines = []
lines = cv2.HoughLinesP(img, rho=1, theta=np.pi/360,
threshold=1, minLineLength=minlength, maxLineGap=gap)
line_list = []
k = 1
judgelength = int(img.shape[0] * 0.95)
for line in lines:
x1, y1, x2, y2 = line[0]
if abs(x1 - x2) <= k and abs(y1 - y2) >= judgelength:
blackline = 1
lineadd_img = cv2.line(img,
(line[0][0], line[0][1]),
(line[0][2], line[0][3]),
(0, 0, 0),
blackline)
cv2.imwrite(cfg.get(user, 'output_folder') +
'/' + filename[:-4] + '_linemod.jpg', lineadd_img)
line = (x1, y1, x2, y2)
line_list.append(line)
line_list.sort(key=itemgetter(0, 1, 2, 3))
df = pd.DataFrame(line_list)
line_count = 0
x1 = line_list[0][0]
for line in line_list:
judge_x1 = line[0]
judge_x2 = line[2]
if abs(judge_x1 - x1) != 0:
if abs(x1-judge_x1) < 2:
x1 = judge_x1
else:
line_count = line_count + 1
x2 = judge_x2
sep_cut = img[:, x1 + 1:x2]
w_imgh = np.ones((5, sep_cut.shape[1]), np.uint8) * 255
sep_cut = cv2.vconcat([w_imgh, sep_cut, w_imgh])
w_imgw = np.ones((sep_cut.shape[0], 5), np.uint8) * 255
sep_cut = cv2.hconcat([w_imgw, sep_cut, w_imgw])
ocr = pytesseract.image_to_string(sep_cut, lang='eng', config='--psm 10')
ocr = ocr.replace('\n', '')
ocr = ocr.replace('\x0c', '')
if ocr != '':
print('OCR:' + str(ocr))
if ocr == '.':
if not os.path.exists(cfg.get(user, 'char_output_folder') + '/_dot'):
os.mkdir(cfg.get(user, 'char_output_folder') + '/_dot')
cv2.imwrite(cfg.get(user, 'char_output_folder') + '/_dot/' + filename[:-4] + '-' + str(line_count) + '_cut.jpg', sep_cut)
else:
if not os.path.exists(cfg.get(user, 'char_output_folder') + '/' + ocr):
os.mkdir(cfg.get(user, 'char_output_folder') + '/' + ocr)
cv2.imwrite(cfg.get(user, 'char_output_folder') + '/' + ocr + '/' + filename[:-4] + '-' + str(line_count) + '_cut.jpg', sep_cut)
x1 = judge_x1*/前半のソースコードは一文字カットのコードのままです。(~83行目)
[https://way2se.ringtrees.com/py_cv2-005/]
一文字毎のカット後にOCRを実施。(85行目)
OCR結果からフォルダの有無を判断。(91行目)
フォルダ作成時の禁止文字があるので、それらは文字列として設定してあげる必要がありますので注意です。
(サンプルコードは . ドットだけですけど同じ要領で可能性があるなら準備してください。)

OCRの結果の精度に依存しますが、OCRの結果毎にフォルダ振り分けができました。
あからさまな置き換えを取り込んでみましたが、時には悪さを引き起こす可能性があるので、どこまで置き換えするかのトレードオフですね。
ただ、想定通りに画像さえ分離できれば、フォルダコントロールも簡単なことがわかりましたね。
後はOCR精度を上げることに注力できれば、機械学習への道に近づきそうです。
~~追記~~
本サンプルコードでは、日本語文字に対応していません。
禁止文字の対応したパターンを公開しました。
併せて参照ください。
[https://way2se.ringtrees.com/py_comb-003/]
